目录 前言 项目构建 部署上线 总结 前言 古诗词是中国文化殿堂的瑰宝,记得曾经在韩国做Exchange Student的时候,看到他们学习我们的古诗词,有中文的还有翻译版的,自己发自内心的骄傲,甚至也会在某些时候背起一些耳熟能详的诗词。
本文将会通过深度学习为我们生成一些古诗词,并将模型部署到Serverless架构上,实现基于Serverless的古诗词生成API。
项目构建 古诗词生成实际上是文本生成,或者说是生成式文本。关于基于深度学习的文本生成,最入门级的读物包括Andrej Karpathy的博客。他使用例子生动讲解了Char-RNN(Character based Recurrent Neural Network)如何用于从文本数据集里学习,然后自动生成像模像样的文本。
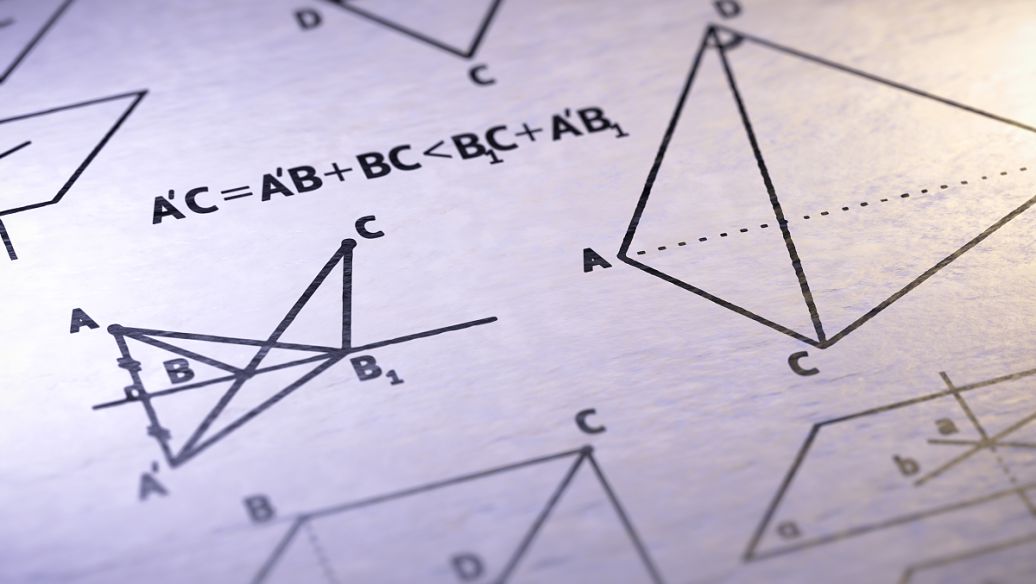
上图直观展示了Char-RNN的原理。以要让模型学习写出“hello”为例,Char-RNN的输入输出层都是以字符为单位。输入“h”,应该输出“e”;输入“e”,则应该输出后续的“l”。输入层我们可以用只有一个元素为1的向量来编码不同的字符,例如,h被编码为“1000”、“e”被编码为“0100”,而“l”被编码为“0010”。使用RNN的学习目标是,可以让生成的下一个字符尽量与训练样本里的目标输出一致。在图一的例子中,根据前两个字符产生的状态和第三个输入“l”预测出的下一个字符的向量为<0.1, 0.5, 1.9, -1.1>,最大的一维是第三维,对应的字符则为“0010”,正好是“l”。这就是一个正确的预测。但从第一个“h”得到的输出向量是第四维最大,对应的并不是“e”,这样就产生代价。学习的过程就是不断降低这个代价。学习到的模型,对任何输入字符可以很好地不断预测下一个字符,如此一来就能生成句子或段落。
本文项目构建参考了Github已有项目:https://github.com/norybaby/poet
通过Clone代码,并且安装相关依赖:
pip3 install tensorflow==1.14 word2vec numpy
通过训练:
python3 train.py
可以看到训练结果:
此时会生成多个模型在output_poem文件夹下,我们只需要保留最好的即可,例如我的训练之后生成的json文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 { "best_model" : "output_poem/best_model/model-20390" , "best_valid_ppl" : 21.441762924194336 , "latest_model" : "output_poem/save_model/model-20390" , "params" : { "batch_size" : 16 , "cell_type" : "lstm" , "dropout" : 0.0 , "embedding_size" : 128 , "hidden_size" : 128 , "input_dropout" : 0.0 , "learning_rate" : 0.005 , "max_grad_norm" : 5.0 , "num_layers" : 2 , "num_unrollings" : 64 }, "test_ppl" : 25.83984375 }
此时,我只需要保存output_poem/best_model/model-20390模型即可。
部署上线 在项目目录下,安装必要依赖:
pip3 install word2vec numpy -t ./
由于tensorflow等是腾讯云云函数内置的package,所以这里无需安装,另外numpy这个package需要在CentOS+Python3.6环境下打包。也可以通过之前制作的小工具打包:https://www.serverlesschina.com/35.html
完成之后,编写函数入口文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import uuid, jsonfrom write_poem import WritePoem, start_modelwriter = start_model() def return_msg (error, msg ): return_data = { "uuid" : str (uuid.uuid1()), "error" : error, "message" : msg } print (return_data) return return_data def main_handler (event, context ): style = json.loads(event["body" ])["style" ] content = json.loads(event["body" ]).get("content" , None ) if style in '34' and not content: return return_msg(True , "请输入content参数" ) if style == '1' : return return_msg(False , writer.free_verse()) elif style == '2' : return return_msg(False , writer.rhyme_verse()) elif style == '3' : return return_msg(False , writer.cangtou(content)) elif style == '4' : return return_msg(False , writer.hide_words(content)) else : return return_msg(True , "请输入正确的style参数" )
同时需要准备好Yaml文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 getUserIp: component: "@serverless/tencent-scf" inputs: name: autoPoem codeUri: ./ exclude: - .gitignore - .git/** - .serverless - .env handler: index.main_handler runtime: Python3.6 region: ap-beijing description: 自动古诗词撰写 namespace: serverless_tools memorySize: 512 timeout: 10 events: - apigw: name: serverless parameters: serviceId: service-8d3fi753 protocols: - http - https environment: release endpoints: - path: /auto/poem description: 自动古诗词撰写 method: POST enableCORS: true
此时,我们就可以通过Serverless Framework CLI部署项目。部署完成之后,我们可以通过PostMan测试我们的接口:
总结 本文通过已有的深度学习项目,在本地进行训练,保存模型,然后将项目部署在腾讯云云函数上,通过与API网关的联动,实现了一个基于深度学习的古诗词撰写的API。
欢迎您关注我的博客,也欢迎转载该博客,转载请注明本文地址: http://bluo.cn/serverless-tencent-field-practice-poem/ 。有关于Serverless等相关问题欢迎联系我:80902630
微信号 抖音号