基于Serverless架构的编程学习小工具
目录
前言
我在很久之前,做过一个在线编程的软件,目前用户量大概有几十万,通过这个APP不仅仅可以进行代码的编写、运行还可以进行编程的学习。自己一直对Serverless架构情有独钟,恰好赶到我的这个APP学习板块被很多人吐槽难用,所以索性就对这个学习板块进行重构,并且打算在重构的时候,直接将这个学习板块搬上Serverless架构。
之所以会想着这次重构模块的时候。直接基于Serverless架构重构,是出于两个方面考虑,第一个方面是Serverless架构在很多时候让个人开发者的运维工作变得简单,尤其是不再关心服务器健康,不容关心流量洪峰(当然,对于我的个人项目而言,也没太多的洪峰),另一个事情就是,Serverless架构的按量付费,虽然水在一定程度上,Serverless架构让所依赖的产品维度变多了,但是实际上,只要控制好,评估好,其成本的节约是非常有效的。
整体设计
数据库设计
这个部分在之前是若干个大模块,现在统一整理到一个模块中进行项目重构,所以这里继续复用之前的数据库:

在这个数据库中,基本上是有四个模块分别是:新闻文章、开发文档、基础教程以及图书资源。其中开发文档包括大分类,子列表以及正文等内容,这里表关联并没有使用外键,而是直接用的id进行表之间的关联。
说实话,这个数据库设计的并不是很好,原因是因为初次构建这个数据部分,绝大部分数据都是在其他站点采集而来,当时模块了快速上线,便直接按照原有格式存储,所以可以认为这个数据库中有很多表的字段其实是无效的,或者针对这个项目是未被使用的。
后端设计
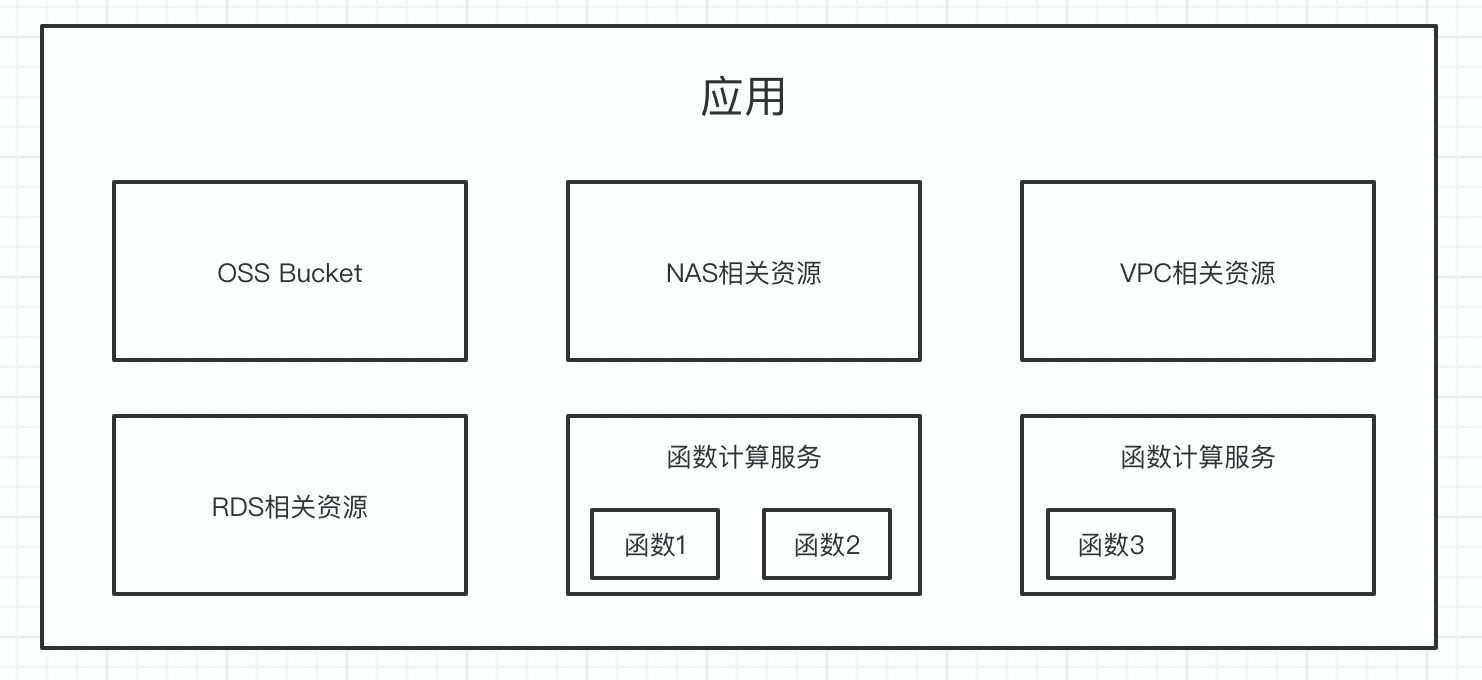
后端将会整体部署到一个函数上,功能整体结构:

整体功能就是云函数绑定API网关触发器,用户访问API网关指定的地址,触发云函数,然后函数在入口处进行功能拆分,请求不同的方法获得对应的数据。
这里要额外说明一下,后端整体接口部署在一个函数的原因,因为我这个模块的使用量并不是非常频繁,所以部署到一个函数上也不会出现超过最大实例的限制,如果超出限制是可以申请扩容的;其次,我所有的接口都是对数据库增删改查,都放入到一个函数中,在一定程度上可以保证容器的活性,降低部分冷启动带来的问题,同时容器的复用,也可以在一定程度上降低后台数据库链接池的压力;除此之外,我所有的接口功能,都是只需要最少的内存(64M)即可完整运行,不会因为个别接口的预估内存较大,进而影响影响整体的成本。所以这里评估之后,是可以将多个接口,放入到一个函数中,对外提供对应的服务。
前端设计
前端设计,预计在学习资源部分需要有8个页面,主要就是科技类新闻、教程、文档、图书等相关功能,通过墨刀绘制的原型图如下:

前端项目开发将会采用Vue.js,并且将其部署到对象存储中,通过腾讯云对象存储的静态网站功能对外提供服务。
项目开发
后端函数开发
后端函数开发主要包括三部分
- 部分资源的初始化,部分资源初始化,需要在函数外进行,这样可以保证复用实例的时候不会再次建立链接,防止数据库连接池出现问题:
1 | def getConnection(dbName): |
- 数据库查询操作
这一部分主要就是针对不同接口查询数据库,例如获取文章分类:
1 | def getArticleCategory(): |
例如获取文章列表:
1 | def getArticleList(cid): |
- 最后一部分就是函数的入口,函数入口部分就是做功能分发和接口识别:
1 | def main_handler(event, context): |
函数部分完成之后,可以配置API网关部分:

在整个后端接口开发过程中,其实并没有遇到什么太大的问题,因为这个学习功能的模块基本上就是对数据库进行查询的操作,所以相对来说非常顺利。
效果预览
整体预览结果:一共包括十几个页面,这里取其中8个主要的页面进行效果展示:

整个页面基本上是还原了设计稿的样子,并且和原有项目进行了部分的整合,无论是列表页面还是图书页面等,数据加载速度表现良好。
通过PostMan进行基本测试:

对接口进行1000次访问测试:

可以看到,接口表现良好,并未出现失败的情况,对该测试结果进行耗时的可视化:

其中最大的时间消耗是219毫秒,最小是27毫秒,平均值是35毫秒,可以看到整体的效果还是非常不错。
这样一个项目开发完成,上线之后,前端部分被放到对象存储中,后端业务被放到函数计算中,触发器使用的是API网关,在监控层面,函数计算有着比较不错的监控纬度:

同时函数并发,弹性伸缩等问题都由云厂商来解决,可以这样说,自从这个组件部署到了Serverless架构上,我所做的操作就是如果业务代码有问题,进行简单修复和简单维护。讲真,整个效果还是不错的。
通过按量付费,可以看到我后端服务产生的费用:

由于云函数没办法看到单个资源的费用,所以整个函数我有几十个,一共花费的费用也远远比服务器的一个月便宜很多。
当然虽然说在计算服务这里整体费用只有几元钱相对来说非常便宜,但是其还有API网关的费用和对象存储的费用,例如API网关费用:

同样,我这里的API网关也是有很多服务的,不仅仅是Anycodes这样一个服务产生的,但是整体加一起2月份只有1元钱,相对来说也是蛮低的。
总结
通过个人项目中的一个子模块重构过程,将该项目部署到Serverless架构上:
在开发过程中,我觉得是蛮方便的,一方面自己不需要在服务器中安装各类软件,也不需要搭建web服务,不需要对web服务进行优化,做的只是读取数据库,按照一定的格式进行return,至于web服务等相关模块交给API网关来实现,整个一个后端开发大概耗时大约是一个多小时;前端开发是比较耗时的,因为我个人不是专业做前端的,所以无论是布局还是逻辑开发,都是有点障碍的,但是也只用了2天时间;所以这个模块从开发到上线只用了2天时间;
项目在部署的时候非常流畅,基于Serverless Framework的开发者工具一键部署,后期更新维护,只需要重新部署即可,线上也是无缝切换,不会出现更新服务造成的服务中断,也不用为更新服务可能造成服务中断而做额外的操作,整体后期更新过程快速且简单易用;
资源消耗部分就是使用按量付费,通过一个月的观察,整个资源消耗是蛮低的,整体性能保证的同时,成本也逐渐的被压低,对于个人开发者来说,确实是一个福音。
通过这样一个简单上Serverless架构的过程,也让我对Serverless架构有了更深入的了解和认识,作为一种新技术或者说新的架构,Serverless的成长还需要一段时间,但是我相信,他的成长,会很快速。
欢迎您关注我的博客,也欢迎转载该博客,转载请注明本文地址: http://bluo.cn/serverless-tencent-project-practice-program-tool/ 。有关于Serverless等相关问题欢迎联系我:80902630
 |  |
| 微信号 | 抖音号 |